
MapReduce is the process of making a list of objects and running an operation over each object in the list (i.e., map) to either produce a new list or calculate a single value (i.e., reduce).
MapReduce Analogy
Let us begin this MapReduce tutorial and try to understand the concept of MapReduce, best explained with a scenario: Consider a library that has an extensive collection of books that live on several floors; you want to count the total number of books on each floor.
Get In-Demand Skills to Launch Your Data Career
Big Data Hadoop Certification Training CourseExplore CourseWhat would be your approach?
Completing this task by yourself would be tedious. A different approach would be to assign each floor to a colleague so that the books from each floor are counted simultaneously by different people. This approach is called parallel processing, making tasks easier to complete.
Technically, parallel processing refers to using multiple machines that contribute their RAM and CPU cores for data processing. This is the concept of the Hadoop framework, where you not only store data across different machines, but you can also process the data locally.
The Apache Hadoop and Spark parallel computing systems let programmers use MapReduce to run models over large distributed sets of data, as well as use advanced statistical and machine learning techniques to make predictions, find patterns, uncover correlations, etc.
Let us understand what MapReduce exactly is in the next section of this MapReduce tutorial.
MapReduce Overview
MapReduce is the processing engine of Hadoop that processes and computes large volumes of data. It is one of the most common engines used by Data Engineers to process Big Data. It allows businesses and other organizations to run calculations to:
- Determine the price for their products that yields the highest profits
- Know precisely how effective their advertising is and where they should spend their ad dollars
- Make weather predictions
- Mine web clicks, sales records purchased from retailers, and Twitter trending topics to determine what new products the company should produce in the upcoming season
Before MapReduce, these calculations were complicated. Now, programmers can tackle problems like these with relative ease. Data scientists have coded complex algorithms into frameworks so that programmers can use them.
Companies no longer need an entire department of Ph.D. scientists to model data, nor do they need a supercomputer to process large sets of data, as MapReduce runs across a network of low-cost commodity machines.
There are two phases in the MapReduce programming model:
- Mapping
- Reducing
The following part of this MapReduce tutorial discusses both these phases.
Mapping and Reducing
A mapper class handles the mapping phase; it maps the data present in different datanodes. A reducer class handles the reducing phase; it aggregates and reduces the output of different datanodes to generate the final output.
Data that is stored on multiple machines pass through mapping. The final output is obtained after the data is shuffled, sorted, and reduced.
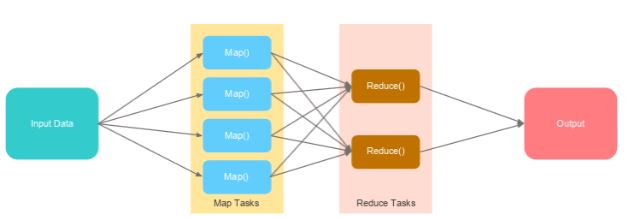
Input Data
Hadoop accepts data in various formats and stores it in HDFS. This input data is worked upon by multiple map tasks.
Map Tasks
Map reads the data, processes it, and generates key-value pairs. The number of map tasks depends upon the input file and its format.
Typically, a file in a Hadoop cluster is broken down into blocks, each with a default size of 128 MB. Depending upon the size, the input file is split into multiple chunks. A map task then runs for each chunk. The mapper class has mapper functions that decide what operation is to be performed on each chunk.
Reduce Tasks
In the reducing phase, a reducer class performs operations on the data generated from the map tasks through a reducer function. It shuffles, sorts, and aggregates the intermediate key-value pairs (tuples) into a set of smaller tuples.
Output
The smaller set of tuples is the final output and gets stored in HDFS.
Let us look at the MapReduce workflow in the next section of this MapReduce tutorial.
MapReduce Workflow
The MapReduce workflow is as shown:
- The input data that needs to be processed using MapReduce is stored in HDFS. The processing can be done on a single file or a directory that has multiple files.
- The input format defines the input specification and how the input files would be split and read.
- The input split logically represents the data to be processed by an individual mapper.
- RecordReader communicates with the input split and converts the data into key-value pairs suitable to be read by the mapper.
- The mapper works on the key-value pairs and gives an intermittent output, which goes for further processing.
- Combiner is a mini reducer that performs mini aggregation on the key-value pairs generated by the mapper.
- Partitioner decides how outputs from combiners are sent to the reducers.
- The output of the partitioner is shuffled and sorted. This output is fed as input to the reducer.
- The reducer combines all the intermediate values for the intermediate keys into a list called tuples.
- The RecordWriter writes these output key-value pairs from reducer to the output files.
- The output data gets stored in HDFS.
The next section of this MapReduce tutorial covers the architecture of MapReduce.
MapReduce Architecture
The architecture of MapReduce is as shown:
There is a client program or an API which intends to process the data. It submits the job to the job tracker (resource manager in the case of Hadoop YARN framework).
Hadoop v1 had a job tracker as master, leading the Task Trackers. In Hadoop v2:
- Job tracker was replaced with ResourceManager
- Task tracker was replaced with NodeManager
The ResourceManager has to assign the job to the NodeManagers, which then handles the processing on every node. Once an application to be run on the YARN processing framework is submitted, it is handled by the ResourceManager.
The data which is stored in HDFS are broken down into one or multiple splits depending on the input format. One or numerous map tasks, running within the container on the nodes, work on these input splits.
There is some amount of RAM utilized for each map task. The same data, which then goes through the reducing phase, would also use some RAM and CPU cores. Internally, there are functions which take care of deciding the number of reducers, doing a mini reduce, reading and processing the data from multiple data nodes.
This is how the MapReduce programming model makes parallel processing work. Finally, the output is generated and gets stored in HDFS.
Let us focus on a use case in the next section of this MapReduce tutorial.
MapReduce Use Case: Global Warming
So, how are companies, governments, and organizations using MapReduce?
First, we give an example where the goal is to calculate a single value from a set of data through reduction.
Suppose we want to know the level by which global warming has raised the ocean’s temperature. We have input temperature readings from thousands of buoys all over the globe. We have data in this format:
(buoy, DateTime, longitude, latitude, low temperature, high temperature)
We would attack this problem in several map and reduce steps. The first would be to run map over every buoy-dateTime reading and add the average temperature as a field:
(buoy, DateTime, longitude, latitude, low, high, average)
Then we would drop the DateTime column and sum these items for all buoys to produce one average temperature for each buoy:
(buoy n, average)
Then the reduce operation runs. A mathematician would say this is a pairwise operation on associative data. In other words, we take each of these (buoy, average) adjacent pairs and sum them and then divide that sum by the count to produce the average of averages:
ocean average temperature = average (buoy n) + average ( buoy n-1) + … + average (buoy 2) + average (buoy 1) / number of buoys
MapReduce Use Case: Drug Trials
Mathematicians and data scientists have traditionally worked together in the pharmaceutical industry. The invention of MapReduce and the dissemination of data science algorithms in big data systems means ordinary IT departments can now tackle problems that would have required the work of Ph.D. scientists and supercomputers in the past.
Let’s take, for example, a company that conducts drug trials to show whether its new drug works against certain illnesses, which is a problem that fits perfectly into the MapReduce model. In this case, we want to run a regression model against a set of patients who have been given the new drug and calculate how effective the drug is in combating the disease.
Suppose the drug is used for cancer patients. We have data points like this:
{ (patient name: John, DateTime: 3/01/2016 14:00, dosage: 10 mg, size of cancer tumor: 1 mm) }
The first step here is to calculate the change in the size of the tumor from one dateTime to next. Different patients would be taking different amounts of the drug, so we would want to know what amount of the drug works best. Using MapReduce, we would try to reduce this problem to some linear relationship like this:
percent reduction in tumor = x (quantity of drug) + y (period of time) + constant value
If some correlation exists between the drug and the reduction in the tumor, then the drug can be said to work. The model would also show to what degree it works by calculating the error statistic.
Let us next look at how MapReduce is helpful in solving problems at a large scale in the next section of this MapReduce tutorial.
Solving Problems on a Large Scale
What makes this a technological breakthrough are two things. First, we can process unstructured data on a large scale, meaning data that does not easily fit into a relational database. Second, it takes the tools of data science and lets them run over distributed datasets. In the past, those could only run on a single computer.
The relative simplicity of the MapReduce tools and their power and application to business, military, science, and other problems explains why MapReduce is growing so rapidly. This growth will only increase as more people come to understand how to apply these tools to their situation.
If you want to learn more about Big Data and Data Engineering, then check out Simplilearn's Professional Certificate Program In Data Engineering, designed in partnership with Purdue University and IBM. The program is perfect for helping you get started in the massive world of Big Data.
