
Thanks to big data, Hadoop has become a familiar term and has found its prominence in today's digital world. When anyone can generate massive amounts of data with just one click, the Hadoop framework is vital. Have you ever wondered what Hadoop is and what all the fuss is about? This article will give you the answers! You will learn all about Hadoop and its relationship with Big Data.
What is Hadoop?
Hadoop is a framework that uses distributed storage and parallel processing to store and manage big data. It is the software most used by data analysts to handle big data, and its market size continues to grow. There are three components of Hadoop:
- Hadoop HDFS - Hadoop Distributed File System (HDFS) is the storage unit.
- Hadoop MapReduce - Hadoop MapReduce is the processing unit.
- Hadoop YARN - Yet Another Resource Negotiator (YARN) is a resource management unit.
Hadoop Through an Analogy
Before jumping into the technicalities of Hadoop, and helping you understand what is Hadoop, let us understand Hadoop through an interesting story. By the end of this story, you will comprehend Hadoop, Big Data, and the necessity for Hadoop.
Introducing Jack, a grape farmer. He harvests the grapes in the fall, stores them in a storage room, and finally sells them in the nearby town. He kept this routing going for years until people began to demand other fruits. This rise in demand led to him growing apples and oranges, in addition to grapes.
Unfortunately, the whole process turned out to be time-consuming and difficult for Jack to do single-handedly.
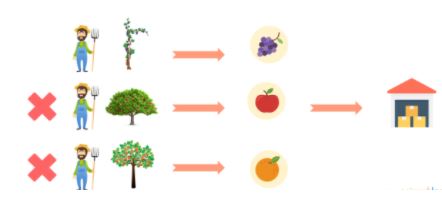
So, Jack hires two more people to work alongside him. The extra help speeds up the harvesting process as three of them can work simultaneously on different products.
However, this takes a nasty toll on the storage room, as the storage area becomes a bottleneck for storing and accessing all the fruits.
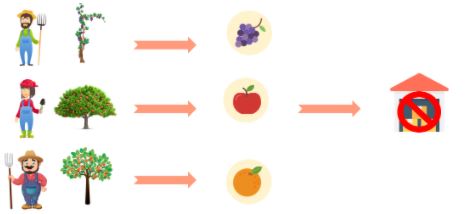
Jack thought through this problem and came up with a solution: give each one separate storage space. So, when Jack receives an order for a fruit basket, he can complete the order on time as all three can work with their storage area.
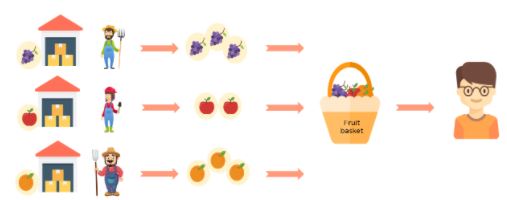
Thanks to Jack’s solution, everyone can finish their order on time and with no trouble. Even with sky-high demands, Jack can complete his orders.
Read More: Simplilearn Big Data Course Review details Md Azhar Hussain journey from a primary domain controller (PDC) to fulfilling his dream of becoming a Big Data Architect. Read how our Big Data Hadoop and Spark Developer course helped make his dream come true.
The Rise of Big Data
So, now you might be wondering how Jack’s story is related to Big Data and Hadoop. Let’s draw a comparison between Jack’s story and Big Data.
Back in the day, there was limited data generation. Hence, storing and processing data was done with a single storage unit and a processor, respectively. In the blink of an eye, data generation increases by leaps and bounds. Not only did it increase in volume but also its variety. Therefore, a single processor was incapable of processing high volumes of different varieties of data. Speaking of varieties of data, you can have structured, semi-structured and unstructured data.
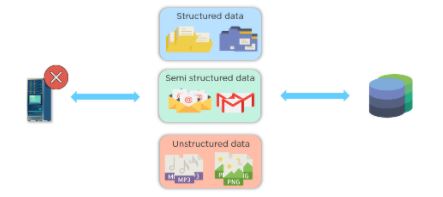
This chart is analogous to how Jack found it hard to harvest different types of fruits single-handedly. Thus, just like Jack’s approach, analysts needed multiple processors to process various data types.
Multiple machines help process data parallelly. However, the storage unit became a bottleneck resulting in a network overhead generation
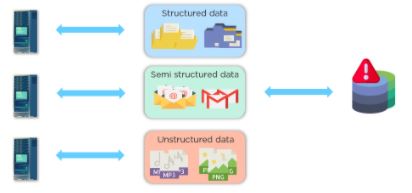
To address this issue, the storage unit is distributed amongst each of the processors. The distribution resulted in storing and accessing data efficiently and with no network overheads. As seen below, this method is called parallel processing with distributed storage.
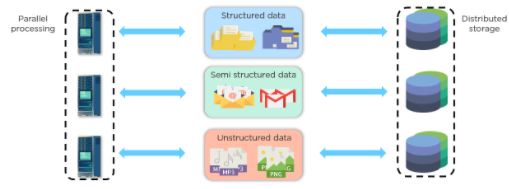
This setup is how data engineers and analysts manage big data effectively. Now, do you see the connection between Jack’s story and big data management?
Big Data and Its Challenges
Big Data refers to the massive amount of data that cannot be stored, processed, and analyzed using traditional ways.
The main elements of Big Data are:
- Volume - There is a massive amount of data generated every second.
- Velocity - The speed at which data is generated, collected, and analyzed
- Variety - The different types of data: structured, semi-structured, unstructured
- Value - The ability to turn data into useful insights for your business
- Veracity - Trustworthiness in terms of quality and accuracy
The main challenges that Big Data faced and the solutions for each are listed below:
|
Challenges |
Solution |
|
Single central storage |
Distributed storage |
|
Serial processing
|
Parallel processing
|
|
Lack of ability to process unstructured data |
Ability to process every type of data |
Lets, understand what is Hadoop in details
Why Is Hadoop Important?
Hadoop is a beneficial technology for data analysts. There are many essential features in Hadoop which make it so important and user-friendly.
- The system is able to store and process enormous amounts of data at an extremely fast rate. A semi-structured, structured and unstructured data set can differ depending on how the data is structured.
- Enhances operational decision-making and batch workloads for historical analysis by supporting real-time analytics.
- Data can be stored by organisations, and it can be filtered for specific analytical uses by processors as needed.
- A large number of nodes can be added to Hadoop as it is scalable, so organisations will be able to pick up more data.
- A protection mechanism prevents applications and data processing from being harmed by hardware failures. Nodes that are down are automatically redirected to other nodes, allowing applications to run without interruption.
Based on the above reasons, we can say that Hadoop is important.
Who Uses Hadoop?
Hadoop is a popular big data tool, used by many companies worldwide. Here’s a brief sample of successful Hadoop users:
- British Airways
- Uber
- The Bank of Scotland
- Netflix
- The National Security Agency (NSA), of the United States
- The UK’s Royal Mail system
- Expedia
Now that we have some idea of Hadoop’s popularity, it’s time for a closer look at its components to gain an understanding of what is Hadoop.
Components of Hadoop
Hadoop is a framework that uses distributed storage and parallel processing to store and manage Big Data. It is the most commonly used software to handle Big Data. There are three components of Hadoop.
- Hadoop HDFS - Hadoop Distributed File System (HDFS) is the storage unit of Hadoop.
- Hadoop MapReduce - Hadoop MapReduce is the processing unit of Hadoop.
- Hadoop YARN - Hadoop YARN is a resource management unit of Hadoop.
Let us take a detailed look at Hadoop HDFS in this part of the What is Hadoop article.
Hadoop HDFS
Data is stored in a distributed manner in HDFS. There are two components of HDFS - name node and data node. While there is only one name node, there can be multiple data nodes.
HDFS is specially designed for storing huge datasets in commodity hardware. An enterprise version of a server costs roughly $10,000 per terabyte for the full processor. In case you need to buy 100 of these enterprise version servers, it will go up to a million dollars.
Hadoop enables you to use commodity machines as your data nodes. This way, you don’t have to spend millions of dollars just on your data nodes. However, the name node is always an enterprise server.
Features of HDFS
- Provides distributed storage
- Can be implemented on commodity hardware
- Provides data security
- Highly fault-tolerant - If one machine goes down, the data from that machine goes to the next machine
Master and Slave Nodes
Master and slave nodes form the HDFS cluster. The name node is called the master, and the data nodes are called the slaves.
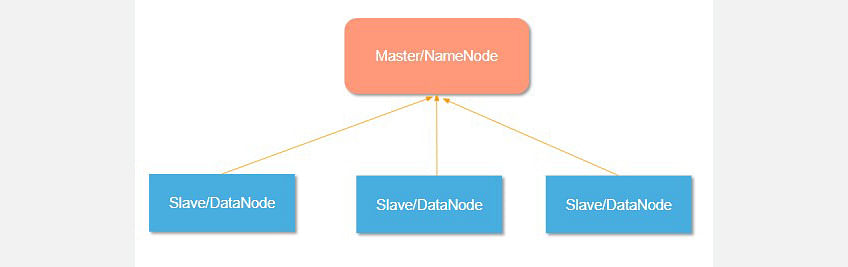
The name node is responsible for the workings of the data nodes. It also stores the metadata.
The data nodes read, write, process, and replicate the data. They also send signals, known as heartbeats, to the name node. These heartbeats show the status of the data node.
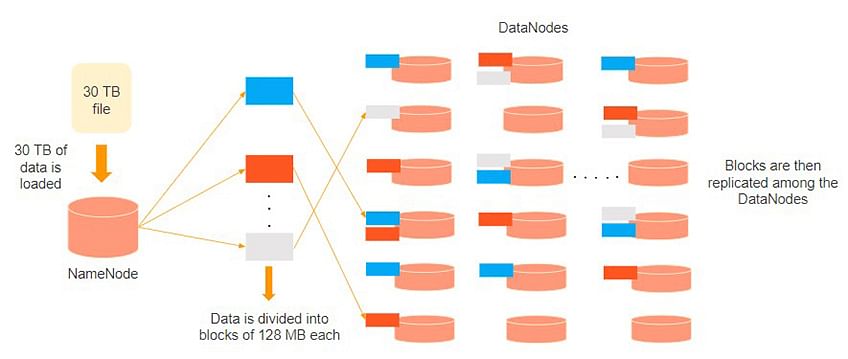
Consider that 30TB of data is loaded into the name node. The name node distributes it across the data nodes, and this data is replicated among the data notes. You can see in the image above that the blue, grey, and red data are replicated among the three data nodes.
Replication of the data is performed three times by default. It is done this way, so if a commodity machine fails, you can replace it with a new machine that has the same data.
Let us focus on Hadoop MapReduce in the following section of the What is Hadoop article.
Hadoop MapReduce
Hadoop MapReduce is the processing unit of Hadoop. In the MapReduce approach, the processing is done at the slave nodes, and the final result is sent to the master node.
A data containing code is used to process the entire data. This coded data is usually very small in comparison to the data itself. You only need to send a few kilobytes worth of code to perform a heavy-duty process on computers.
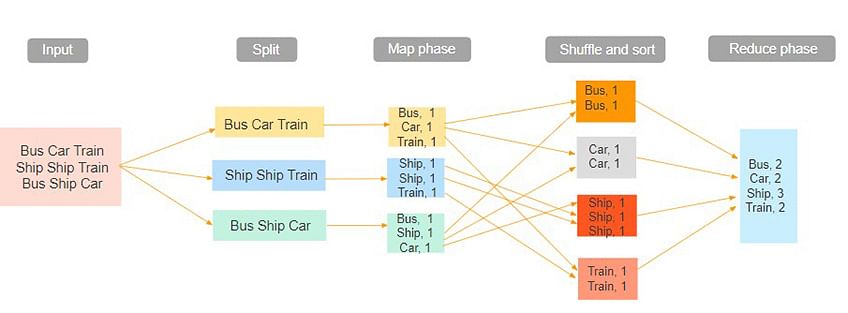
The input dataset is first split into chunks of data. In this example, the input has three lines of text with three separate entities - “bus car train,” “ship ship train,” “bus ship car.” The dataset is then split into three chunks, based on these entities, and processed parallelly.
In the map phase, the data is assigned a key and a value of 1. In this case, we have one bus, one car, one ship, and one train.
These key-value pairs are then shuffled and sorted together based on their keys. At the reduce phase, the aggregation takes place, and the final output is obtained.
Hadoop YARN is the next concept we shall focus on in the What is Hadoop article.
Hadoop YARN
Hadoop YARN stands for Yet Another Resource Negotiator. It is the resource management unit of Hadoop and is available as a component of Hadoop version 2.
- Hadoop YARN acts like an OS to Hadoop. It is a file system that is built on top of HDFS.
- It is responsible for managing cluster resources to make sure you don't overload one machine.
- It performs job scheduling to make sure that the jobs are scheduled in the right place
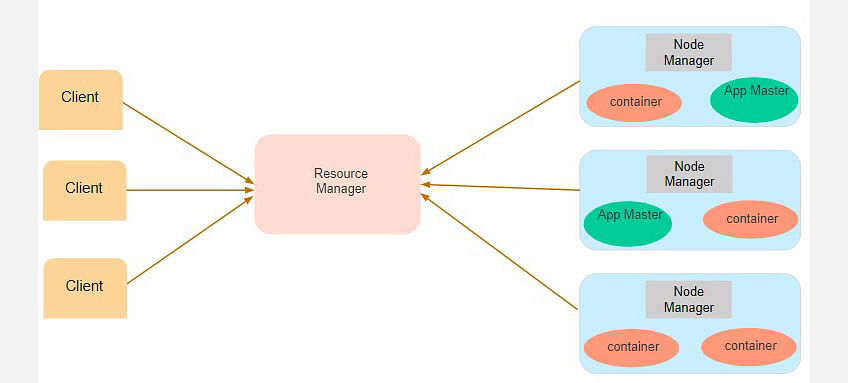
Suppose a client machine wants to do a query or fetch some code for data analysis. This job request goes to the resource manager (Hadoop Yarn), which is responsible for resource allocation and management.
In the node section, each of the nodes has its node managers. These node managers manage the nodes and monitor the resource usage in the node. The containers contain a collection of physical resources, which could be RAM, CPU, or hard drives. Whenever a job request comes in, the app master requests the container from the node manager. Once the node manager gets the resource, it goes back to the Resource Manager.
How Does Hadoop Work?
The primary function of Hadoop is to process the data in an organised manner among the cluster of commodity software. The client should submit the data or program that needs to be processed. Hadoop HDFS stores the data. YARN, MapReduce divides the resources and assigns the tasks to the data. Let’s know the working of Hadoop in detail.
- The client input data is divided into 128 MB blocks by HDFS. Blocks are replicated according to the replication factor: various DataNodes house the unions and their duplicates.
- The user can process the data once all blocks have been put on HDFS DataNodes.
- The client sends Hadoop the MapReduce programme to process the data.
- The user-submitted software was then scheduled by ResourceManager on particular cluster nodes.
- The output is written back to the HDFS once processing has been completed by all nodes.
Hadoop Distributed File System:
HDFS is known as the Hadoop distributed file system. It is the allocated File System. It is the primary data storage system in Hadoop Applications. It is the storage system of Hadoop that is spread all over the system. In HDFS, the data is once written on the server, and it will continuously be used many times according to the need. The targets of HDFS are as follows.
- The ability to recover from hardware failures in a timely manner
- Access to Streaming Data
- Accommodation of Large data sets
- Portability
Hadoop Distributed File System has two nodes included in it. They are the Name Node and Data Node.
Name Node:
Name Node is the primary component of HDFS. Name Node maintains the file systems along with namespaces. Actual data can not be stored in the Name Node. The modified data, such as Metadata, block data etc., can be stored here.
Data Node:
Data Node follows the instructions given by the Name Node. Data Nodes are also known as ‘slave Nodes’. These nodes store the actual data provided by the client and simply follow the commands of the Name Node.
Job Tracker:
The primary function of the Job Tracker is resource management. Job Tracker determines the location of the data by communicating with the Name Node. Job Tracker also helps in finding the Task Tracker. It also tracks the MapReduce from Local Node to Slave Node. In Hadoop, there is only one instance of Job Trackers. Job Tracker monitors the individual Task Tracker and tracks the status. Job Tracker also helps in the execution of MapReduce in Hadoop.
Task Tracker:
Task Tracker is the slave daemon in the cluster which accepts all the instructions from the Job Tracker. Task Tracker runs on its process. The task trackers monitor all the tasks by capturing the input and output codes. The Task Tracker helps in mapping, shuffling and reducing the data operations. Task Tracker arranges different slots to perform different tasks. Task Tracker continuously updates the status of the Job Tracker. It also informs about the number of slots available in the cluster. In case the Task Tracker is unresponsive, then Job Tracker assigns the work to some other nodes.
How Hadoop Improves on Traditional Databases
Understanding what is Hadoop requires further understanding on how it differs from traditional databases.
Hadoop uses the HDFS (Hadoop Data File System) to divide the massive data amounts into manageable smaller pieces, then saved on clusters of community servers. This offers scalability and economy.
Furthermore, Hadoop employs MapReduce to run parallel processings, which both stores and retrieves data faster than information residing on a traditional database. Traditional databases are great for handling predictable and constant workflows; otherwise, you need Hadoop’s power of scalable infrastructure.
5 Advantages of Hadoop for Big Data
Hadoop was created to deal with big data, so it’s hardly surprising that it offers so many benefits. The five main benefits are:
- Speed. Hadoop’s concurrent processing, MapReduce model, and HDFS lets users run complex queries in just a few seconds.
- Diversity. Hadoop’s HDFS can store different data formats, like structured, semi-structured, and unstructured.
- Cost-Effective. Hadoop is an open-source data framework.
- Resilient. Data stored in a node is replicated in other cluster nodes, ensuring fault tolerance.
- Scalable. Since Hadoop functions in a distributed environment, you can easily add more servers.
How Is Hadoop Being Used?
Hadoop is being used in different sectors to date. The following sectors have the usage of Hadoop.
1. Financial Sectors:
Hadoop is used to detect fraud in the financial sector. Hadoop is also used to analyse fraud patterns. Credit card companies also use Hadoop to find out the exact customers for their products.
2. Healthcare Sectors:
Hadoop is used to analyse huge data such as medical devices, clinical data, medical reports etc. Hadoop analyses and scans the reports thoroughly to reduce the manual work.
3. Hadoop Applications in the Retail Industry:
Retailers use Hadoop to improve their sales. Hadoop also helped in tracking the products bought by the customers. Hadoop also helps retailers to predict the price range of the products. Hadoop also helps retailers to make their products online. These advantages of Hadoop help the retail industry a lot.
4. Security and Law Enforcement:
The National Security Agency of the USA uses Hadoop to prevent terrorist attacks. Data tools are used by the cops to chase criminals and predict their plans. Hadoop is also used in defence, cybersecurity etc.
5. Hadoop Uses in Advertisements:
Hadoop is also used in the advertisement sector too. Hadoop is used for capturing video, analysing transactions and handling social media platforms. The data analysed is generated through social media platforms like Facebook, Instagram etc. Hadoop is also used in the promotion of the products.
There are many more advantages of Hadoop in daily life as well as in the Software sector too.
Hadoop Use Case
In this case study, we will discuss how Hadoop can combat fraudulent activities. Let us look at the case of Zions Bancorporation. Their main challenge was in how to use the Zions security team’s approaches to combat fraudulent activities taking place. The problem was that they used an RDBMS dataset, which was unable to store and analyze huge amounts of data.
In other words, they were only able to analyze small amounts of data. But with a flood of customers coming in, there were so many things they couldn’t keep track of, which left them vulnerable to fraudulent activities
They began to use parallel processing. However, the data was unstructured, and analyzing it was not possible. Not only did they have a huge amount of data that could not get into their databases, but they also had unstructured data.
Hadoop enabled the Zions’ team to pull all that massive amounts of data together and store it in one place. It also became possible to process and analyze the huge amounts of unstructured data that they had. It was more time-efficient, and the in-depth analysis of various data formats became easier through Hadoop. Zions’ team could now detect everything from malware, spears, and phishing attempts to account takeovers.
Challenges of Using Hadoop
Despite Hadoop’s awesomeness, it’s not all hearts and flowers. Hadoop comes with its own issues, such as:
- There’s a steep learning curve. If you want to run a query in Hadoop’s file system, you need to write MapReduce functions with Java, a process that is non-intuitive. Also, the ecosystem is made up of lots of components.
- Not every dataset can be handled the same. Hadoop doesn’t give you a “one size fits all” advantage. Different components run things differently, and you need to sort them out with experience.
- MapReduce is limited. Yes, it’s a great programming model, but MapReduce uses a file-intensive approach that isn’t ideal for real-time interactive iterative tasks or data analytics.
- Security is an issue. There is a lot of data out there, and much of it is sensitive. Hadoop still needs to incorporate the proper authentication, data encryption, provisioning, and frequent auditing practices..
Got a clear understanding of what is Hadoop? Check out what you should do next.
Looking forward to becoming a Hadoop Developer? Check out the Hadoop Certification Training Course and get certified today.
Conclusion
Hadoop is a widely used Big Data technology for storing, processing, and analyzing large datasets. After reading this article on what is Hadoop, you would have understood how Big Data evolved and the challenges it brought with it. You understood the basics of Hadoop, its components, and how they work. Do you have any questions related to what is Hadoop article? If you have, then please put it in the comments section of this article. Our team will help you solve your queries.
If you want to grow your career in Big Data and Hadoop, then you can check Big Data Engineer Course.
